Building MCP-based AI systems that reason with models and execute through deterministic tools
As engineers, we’re skeptical of systems that aren’t deterministic. Many current AI applications, which bundle reasoning and execution into a single model, are fundamentally unreliable for mission-critical tasks. A travel bot that hallucinates a visa requirement isn’t just a bad user experience; it’s a system failure.
I’ve been building with a simple principle that radically improves reliability: separate the thinker from the doer. I call it the “Thin AI, Thick Server” pattern.
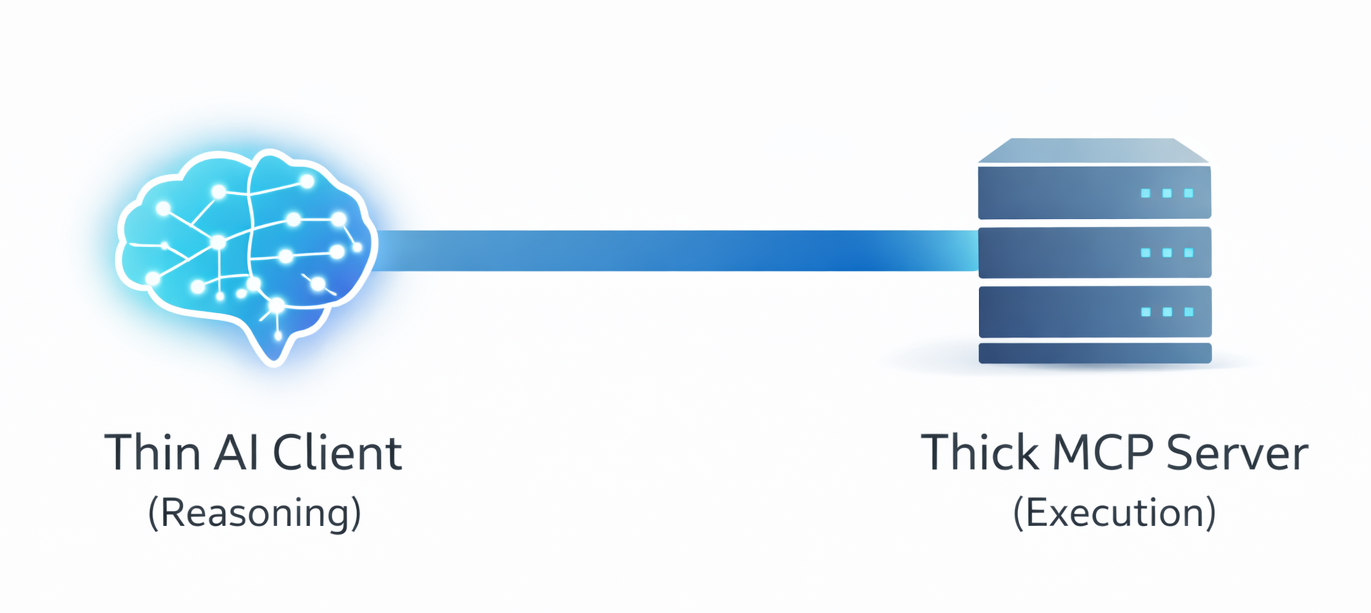
The AI client is the “thin” thinker. Its only job is to understand user intent, orchestrate a plan, and make tool calls. It holds no business logic.
The MCP server is the “thick” doer. It exposes a set of deterministic, versioned tools. It owns all business logic, validation, and execution.
The Core Principle: Separation of Concerns
This isn’t a new idea, but it’s critical in the context of LLMs.
Thin AI Client (Orchestrator):
Responsibilities: Deconstruct user prompts, sequence tool calls, and synthesize results.
Key Characteristic: Stateless and unaware of implementation details. It operates purely on the public contract of the tools.
Thick MCP Server (Executor):
Responsibilities: Expose a rigid API with versioned, schema-enforced tools (
/v1/search_flights). Handle all execution logic, error handling, and policy enforcement (e.g., budget limits, data privacy).Key Characteristic: Deterministic and authoritative. It is the single source of truth for what the system can do.
Why This Architecture Works
Reliability: The system’s capabilities are defined by the server’s hard-coded tools, not the model’s whims. Hallucinated function calls are impossible.
Traceability: Every output is directly attributable to a sequence of tool calls. Debugging becomes a matter of inspecting API logs, a familiar process for any engineer.
Governance: Critical rules—security, compliance, budget constraints—are enforced in the server-side code, immune to prompt manipulation.
Key Learnings from Implementation
Contracts Are King: The most significant reliability gains came from enforcing strict JSON schemas for every tool’s request and response, not from prompt engineering. A well-defined contract eliminates ambiguity.

Design Atomic Tools: Each tool should do one thing well.
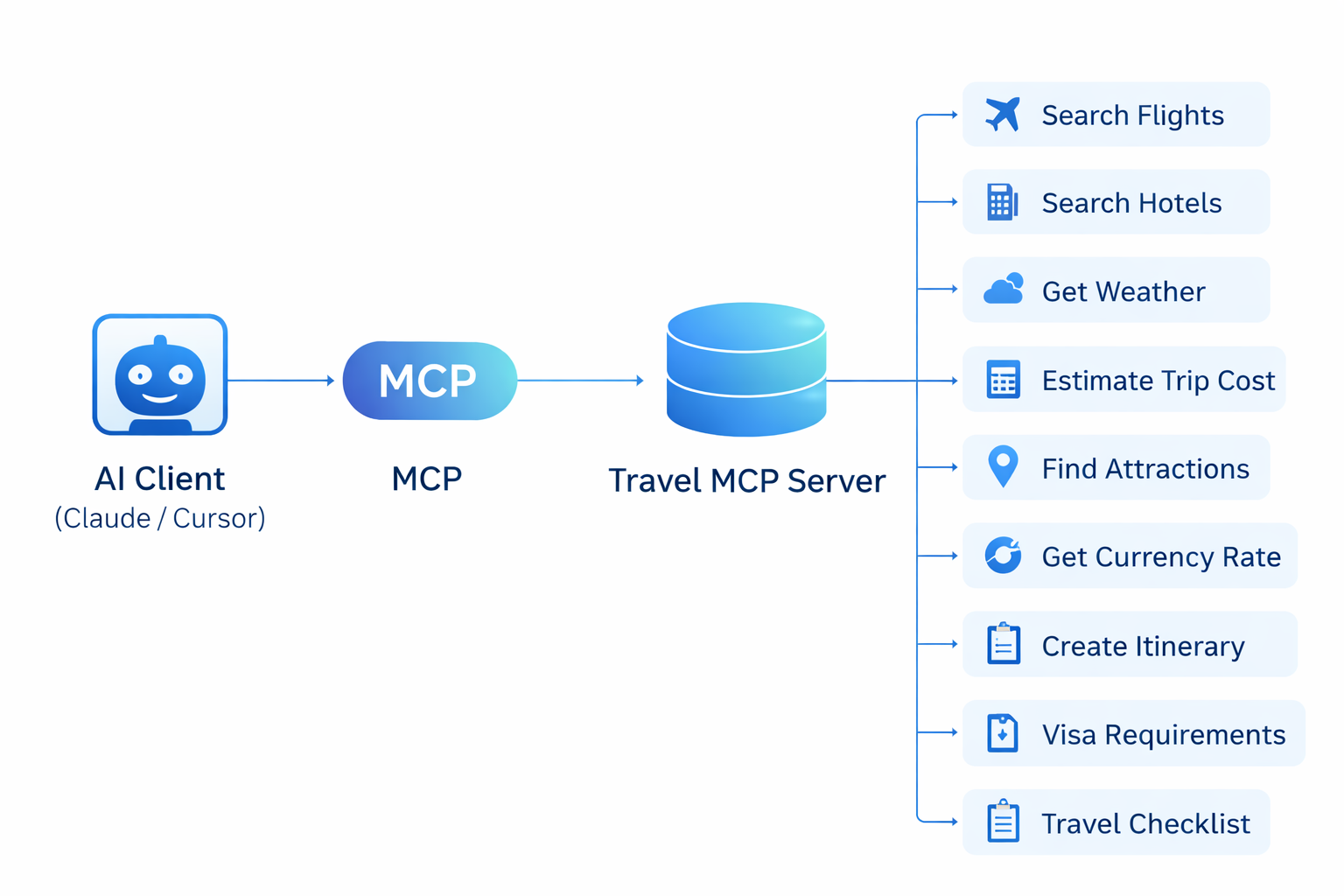
search_flightsfinds flights.estimate_trip_costcalculates costs. The LLM’s job is to compose these atomic units into a complex workflow. Don’t build monolithic tools that hide orchestration logic.Build for Trust: The most valued tools were often the simplest.
visa_requirementsandtravel_checklistprovided concrete, verifiable answers that built user confidence far more than a perfectly worded itinerary.
The path to production-ready AI isn’t better prompts; it’s better architecture. By treating the LLM as a reasoning engine and building our business logic into a robust, tool-driven server, we can build AI systems that are not just impressive, but trustworthy.

Leave a comment